

進化が非常に速いAI業界ですが、最近はRAG (検索拡張生成) を行えるサービスがじわじわと活発になっている印象です。
今日はそんなRAGについて、ファインチューニングとの違いを述べる形で解説し、実際にRAGが手軽に行えるサービスもご紹介していきます。
しばしお付き合いください。
(参照記事)
https://leapwell.co.jp/tech_column/blog-finetuning-vs-rag
◼︎ファインチューニングについて
「ファインチューニング」の方が耳馴染みのある方は多いのではないでしょうか。
ファインチューニングは、AIモデルに新しい知識や特定のタスクを学習させるプロセスです。モデルに対してトレーニングデータを用意し、そのデータをAIに学習させます。モデルは既存の知識を基に新しい情報を習得していきます。
小出しでフライングですが、RAGではモデル自体の知能は変わらないのに対し、ファインチューニングでは、モデルがトレーニングを通じて新しい知識を自身の経験として取り入れるため、モデルの知能も特定のタスクに向けて変化します。
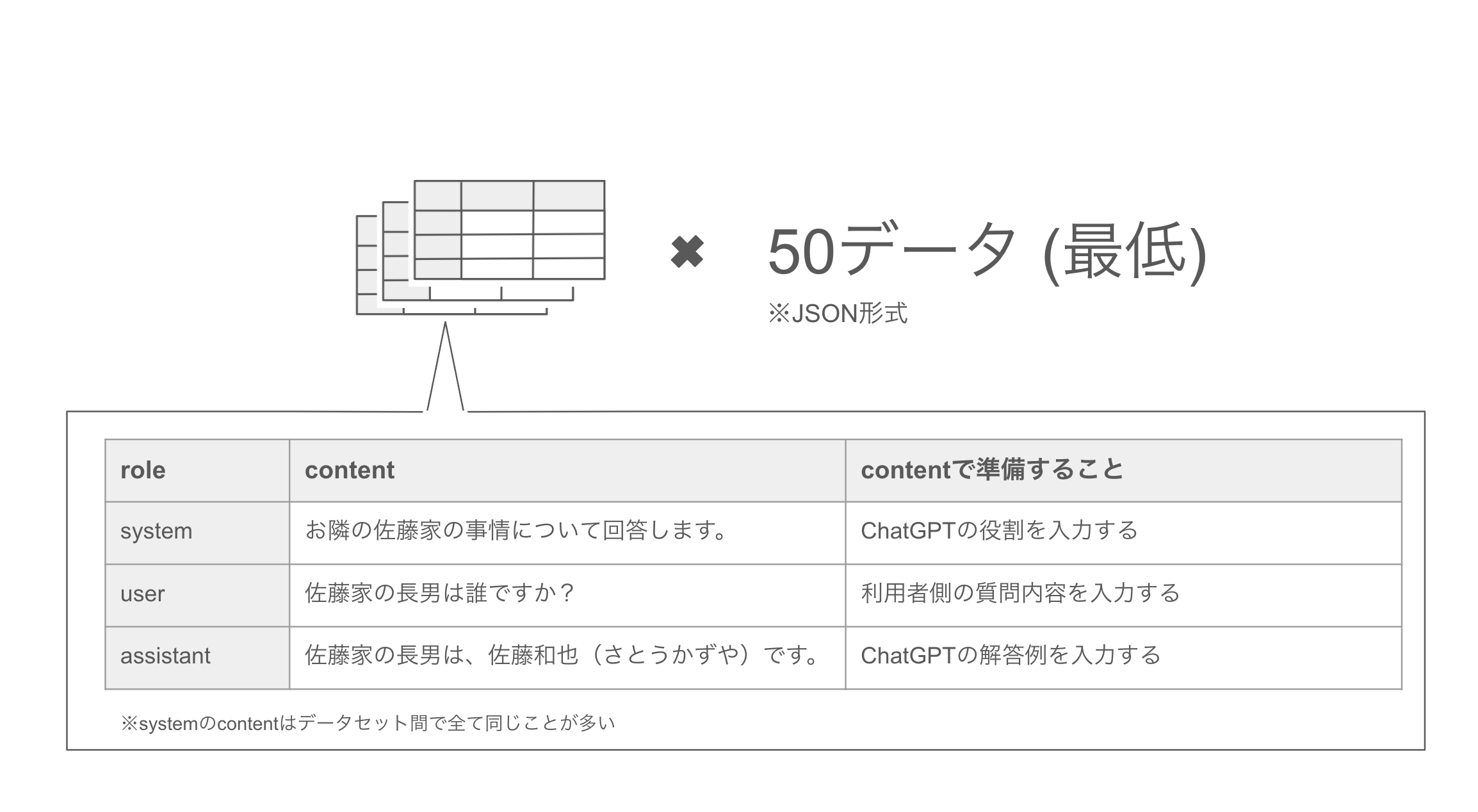
ファインチューニングで一番大変なのは、学習データの準備や学習時間と費用が必要なことです。
OpenAIの公式サイトによれば、<役割 / 質問 / 回答> の形式で少なくとも50個の学習データセットを準備することが推奨されています。
このデータセットを作成するだけでなく、学習結果を見ながら精度を上げるための調整や手間も必要です。
◼︎RAGについて
RAGは、事前に用意されたアップロードファイルを参照しながら回答を生成する技術です。
質問内容がマニュアルに記載されている情報に基づいていれば、RAGは適切な回答を提供できます。
質問に対して関連する情報をマニュアルから自動的に検索し、その情報をもとに回答を生成するイメージです。
もっと具体的に言えば、プロンプトを与えられた際に、関連性の高い部分をマニュアル内から検索し、その結果をプロンプトに追加してから回答を生成するという手法です。
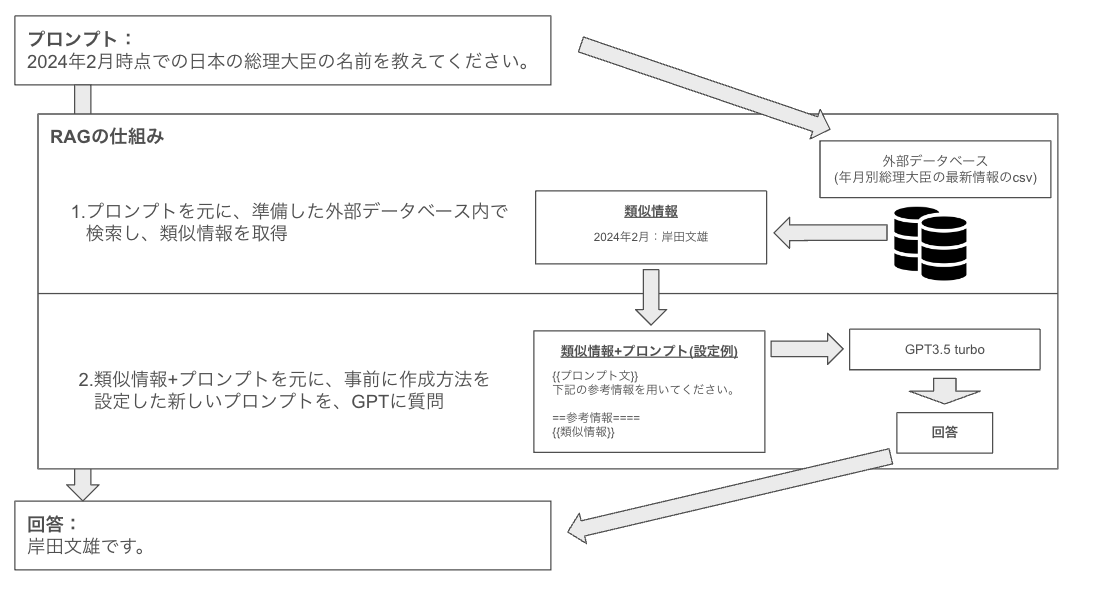
RAGには利点がありますが、もちろん欠点も存在します。
ファイルの内容を理解しているわけではなく、単にマニュアルを参照して関連情報を探し出しているだけであるため、回答の質はマニュアルの内容と検索アルゴリズムの精度にどうしても依存してしまいます。
しかしながら、(状況とニーズに応じた使い分けは必要ですが、) 比較的RAGの方がハードルが低いことは明らかですね。
◼︎RAGを行えるサービス
最後にRAGが行えるサービスを一つ紹介して終わりにします。
先日世に出てきた「NotebookLM」というサービスをご存知でしょうか。
https://notebooklm.google/
Googleが出しているサービスで、手軽にRAGを実行できます。
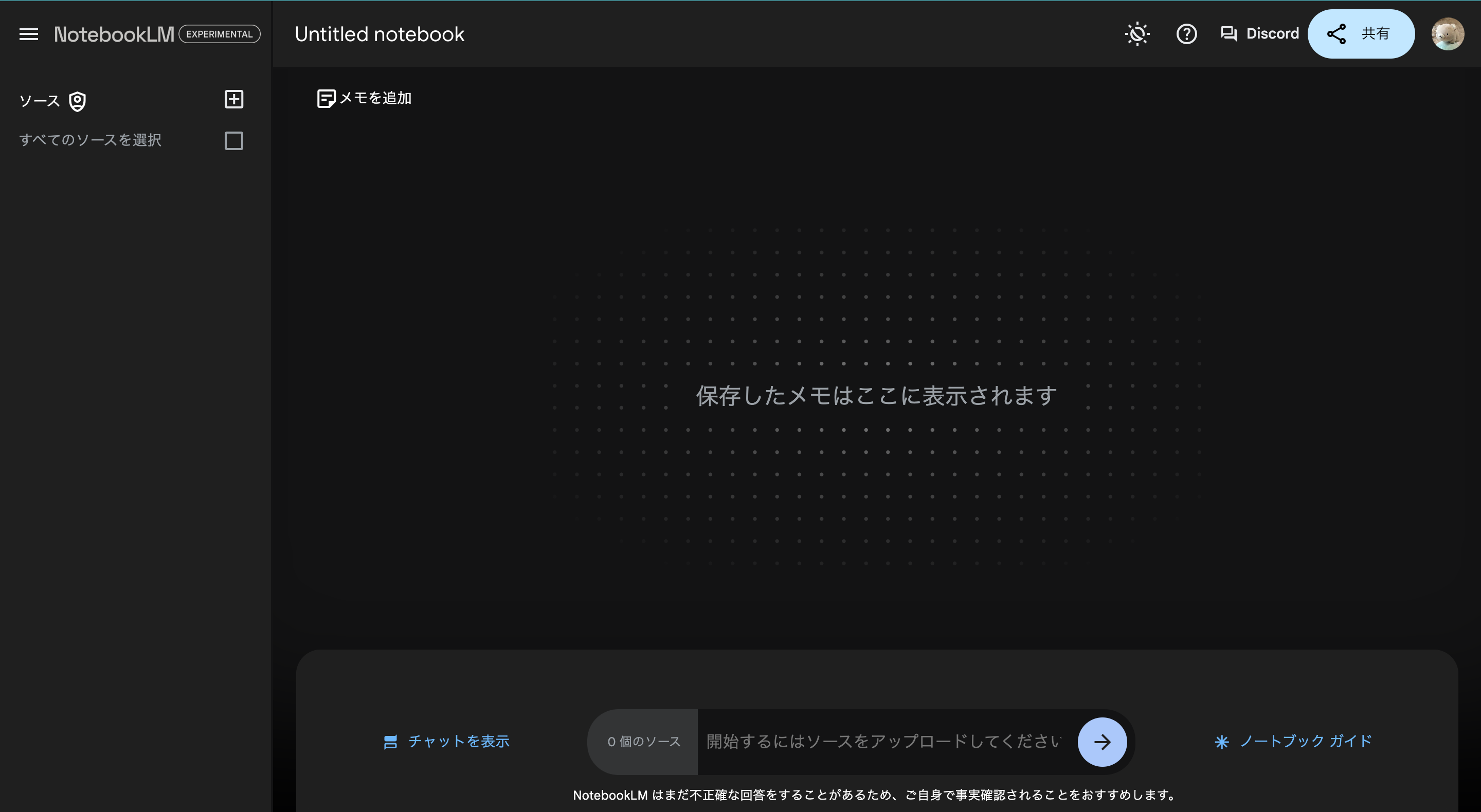
・左側「ソース」にプラス (+) マークからファイルを追加する
・チャットで質問を投げる
やることは最低限これだけです。
返ってきた回答には番号が振られていて、クリックするとどこを参照したのかハイライトで確認ができます。
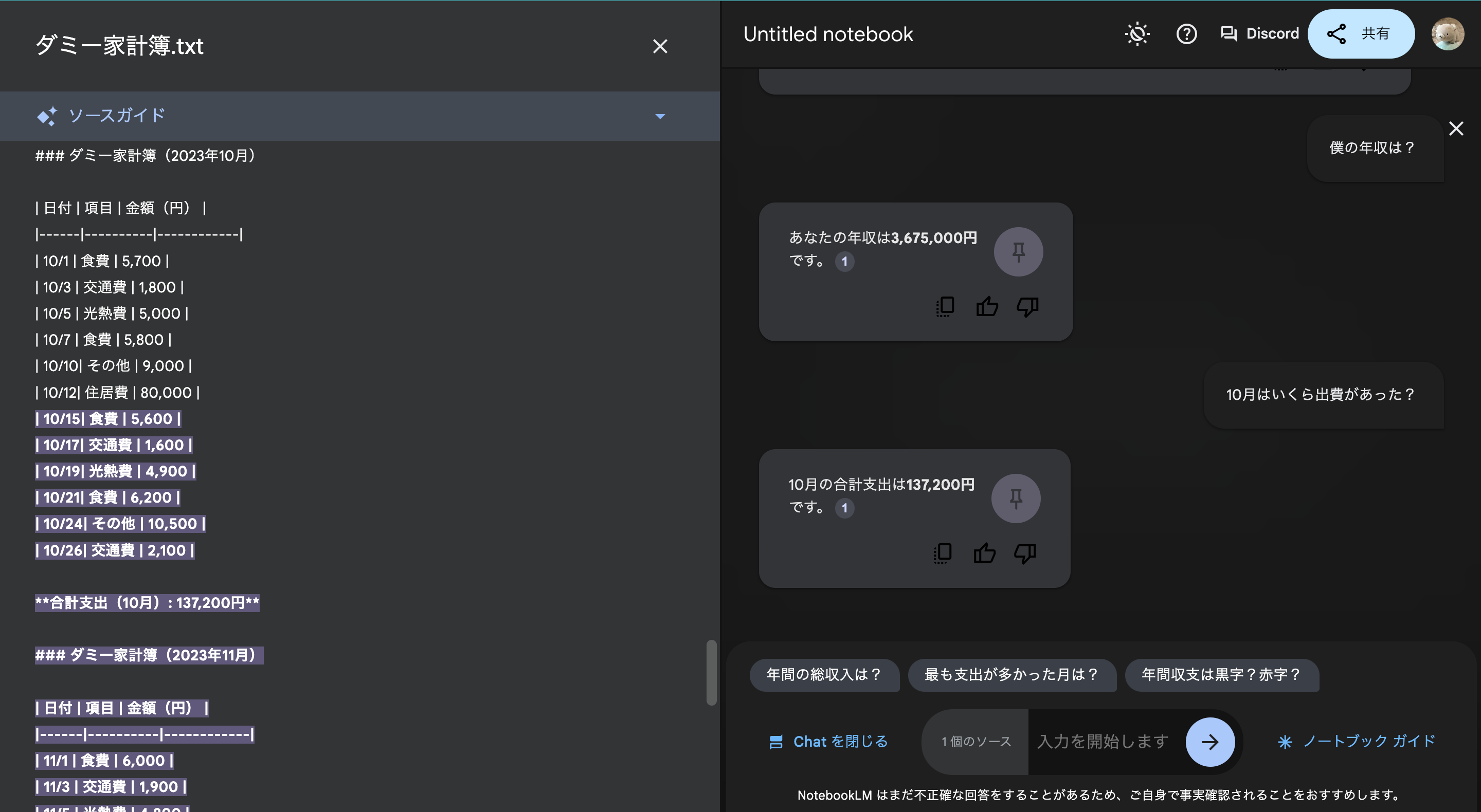
詳細やもっと具体的な機能・使い方は以下のサイトに良くまとまっていますので、ぜひご覧ください。
https://weel.co.jp/media/innovator/notebooklm/
今回もお読みいただきありがとうございました!