AIが設計をレビューし、別のAIが修正する——「設計検証ループ」という新しいアプローチ
ソフトウェア開発において、設計の品質がその後の実装全体に影響を与えることはよく知られています。しかし「設計レビュー」は属人的になりがちで、時間もかかる工程です。私たちはこの課題に対して、複数のAIモデルを組み合わせた「設計検証ループ」という仕組みを構築しました。
本記事で紹介する内容は 2026 年 2 月時点のものです。 当時はまだ Sonnet 4.5 の時代でした。
着想のきっかけ——検証ループはコードだけのものではない
Claude Codeの開発者であるBoris Cherny氏は、検証ループの重要性について自身のXで言及しており、フィードバックループがあれば最終結果の品質は2〜3倍向上すると述べています。1)
この考え方はコードの実装フェーズに向けたものでしたが、私は疑問を持ちました。「設計段階で検証ループを回したらどうなるか」。当時、要件定義や設計は人の手で行うべきという認識が主流でした。それでも試してみると、設計の品質が大きく変わることが確認できました。
なぜレビューと修正を別のAIに担当させるのか
最初に浮かぶ疑問は「なぜ1つのAIで完結させないのか」という点です。
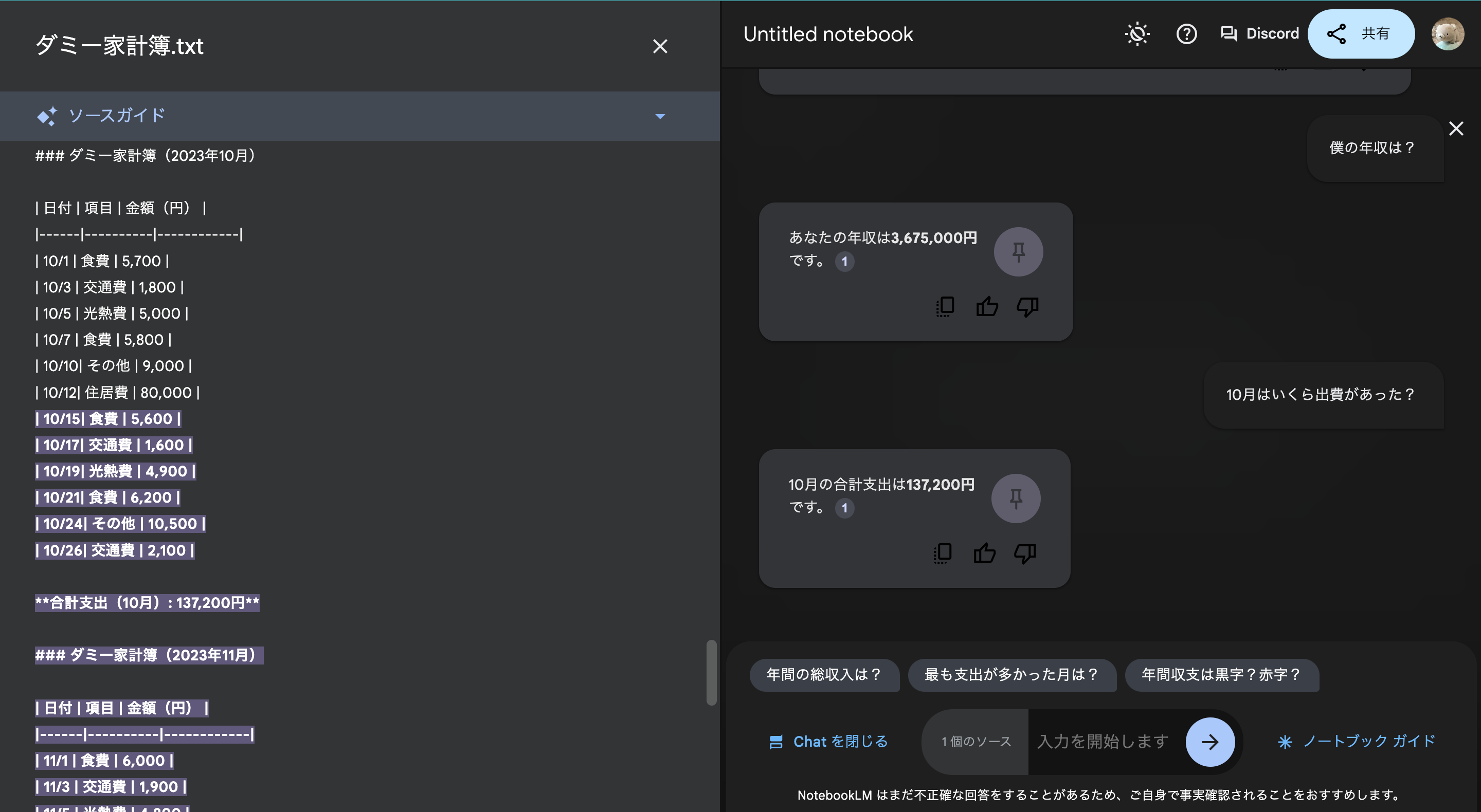
理由は単純で、作成者が自分の成果物をレビューすると、評価が甘くなるからです。これは人間のレビューでも起きる現象ですが、AIも同様です。Anthropicの公式ドキュメントには「A fresh context improves code review since Claude won’t be biased toward code it just wrote.」2)(筆者訳:新鮮なコンテキストはコードレビューの質を高める。Claudeは自分が書いたコードへのバイアスを持たない状態でレビューできるからだ)と記されています。自分が生成した設計を自分でレビューさせると、見落としが増え、問題を指摘しにくくなる傾向があります。
そのため、このループではClaudeがレビューを担当し、GPT-5が修正を担当するという役割分担を採用しています。異なるモデルが異なる視点で関わることで、指摘の客観性が上がります。
ループの流れ
1. 要件・仕様の入力(プランモード)
まず要件と仕様を整理し、設計案を作成します。この段階ではコードを書かず、設計の方針を固めることに集中します。
2. Claudeがレビュー
設計案に対してClaudeがレビューを実施し、問題点を指摘します。評価は以下10の観点に基づき、0〜100のスコアで数値化されます。
| # | 観点 |
|---|---|
| 1 | 完全性 — 必要な情報がすべて含まれているか |
| 2 | 一貫性 — 設計の各部分が矛盾していないか |
| 3 | 実装可能性 — 現実的に実装できるか |
| 4 | 拡張性 — 将来の変更に対応できるか |
| 5 | 保守性 — メンテナンスしやすいか |
| 6 | パフォーマンス — 性能上の問題はないか |
| 7 | セキュリティ — リスクはないか |
| 8 | テスタビリティ — テストしやすい設計か |
| 9 | ベストプラクティス — 業界標準に沿っているか |
| 10 | 技術選択 — 技術スタックは適切か |
なお、このスコアは客観的な計算式ではなく、モデルがプロンプトに従って主観的に判断した値です。同じ設計でもモデルによってスコアがブレる可能性があります。これがレビュアーモデルを途中で変えると整合性が崩れやすい理由でもあります。
3. GPT-5が修正
Claudeの指摘を受けてGPT-5が設計を修正します。修正は以下の優先順位で行われます。
- P0(必須): 全件の指摘が修正済みであること
- P1(改善): 1件ずつ、観点をローテーションしながら改善
- 反復1: セキュリティ
- 反復2: 設計原則(SOLID / 責務分離)
- 反復3: テスト戦略
- 反復4: パフォーマンス……
4. スコア判定
修正後の設計を再評価します。
– スコア < 85点 かつ 指摘あり → ループを継続
– スコア ≥ 85点 または 指摘ゼロ → 実装フェーズへ移行
運用して分かったこと
85点を超えると実装レベルのコードが出てくる
スコアが85点を超えた設計から生成されるコードは、実装にそのまま使えるクオリティになることが確認できました。85点という目標値は、過度な完璧主義を避けつつ実用的な品質を担保するバランスとして機能しています。
レビュアーはClaude以外も選択できる
レビュアーのモデルはGPTやGeminiに差し替えることも可能です。ただし、スコアはモデルの主観的判断に依存するため、レビュアーを途中で変えると基準が変わりスコアの連続性が失われます。1つのループは同じモデルで通すことを推奨します。
まとめ
「AIに作らせてAIにレビューさせる」という構成は一見シンプルに見えますが、同じAIに作成とレビューを兼任させないという設計が品質向上の鍵です。
Boris Cherny氏が述べるように、検証ループの構築はシンプルです。「AIに結果を見るツールを与え、そのツールについて教える。これだけ」。設計フェーズにこの考え方を持ち込んだことで 、実装品質が大きく変わることが実感できました。
後書き
また、今回の取り組みでは、OSS 的な“差分前提の学び方”を意識し、 モデルやツールの更新に合わせて、必要な部分だけを検証・更新するプロセスを取り入れています。 これは「毎回ゼロから学び直す」のではなく、 変化した部分だけを追い、差分だけを反映するというアプローチです。
本記事で紹介した内容は 2026 年 2 月時点のもので、 当時はまだ Sonnet 4.5 の時代でした。 その後の Claude Code をはじめとした LLM モデルの進化の速さを見ると、 差分駆動の学習方法こそが、変化に追随するための現実的なアプローチだと改めて感じます。
今後も、急速に変化し続ける技術に対して、 差分を捉えながら理解を更新し続ける姿勢で、変化に向き合い続けたいと思います。
参考文献
1) Boris Cherny.X投稿.2025-01.https://x.com/bcherny/status/2007179861115511237,(参照 2026-01-21).
2) Anthropic.”Best Practices for Claude Code”.Anthropic Claude Code Docs.https://code.claude.com/docs/en/best-practices,(参照 2026-04-13).